Training Best Practices#
Panoptic segmentation is a powerful framework that allows segmentation of arbitrary combinations of instance and semantic classes. This is especially relevant for EM data in which some organelles like mitochondria should have individual instances segmented while others like ER only make sense in the context of semantic segmentation.
Note
If you already have a labeled dataset (like CEM-MitoLab). The only requirement to use finetuning or training is that you put the images into the correct directory structure. That structure is:
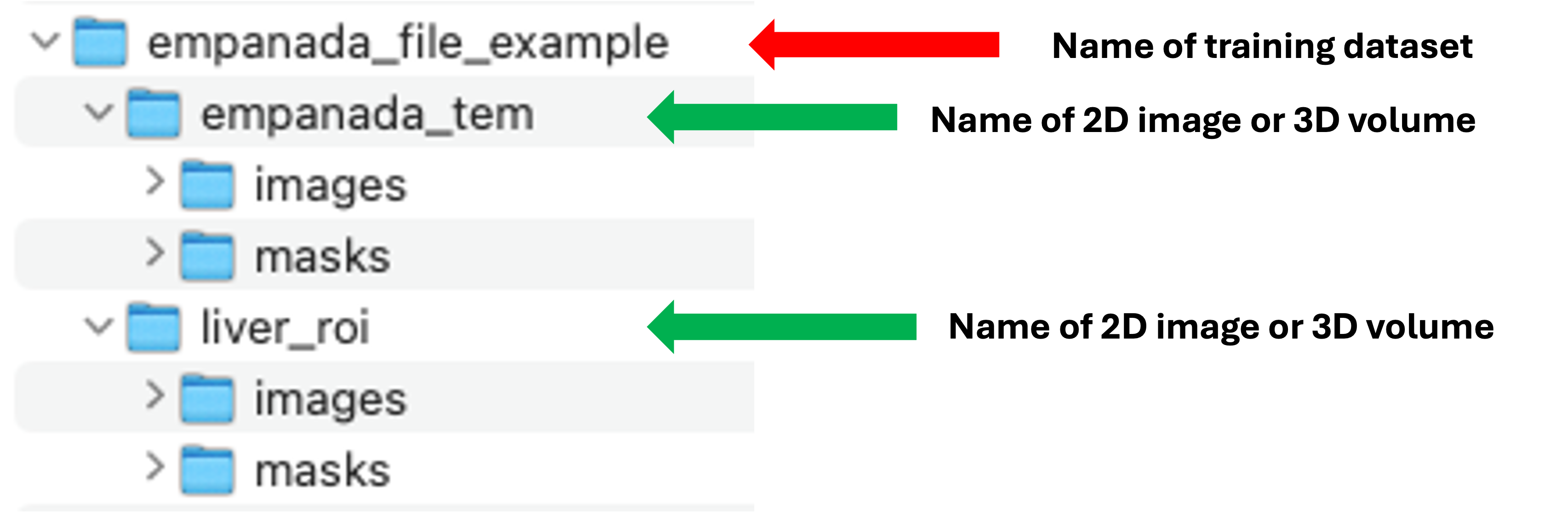
name_of_training_dataset
name_of_2D_image_or_3D_volume
images
image1.tiff
image2.tiff
masks
image1.tiff
image2.tiff
There can be multiple name_of_2D_image_or_3D_volume subdirectories. Each must have a subdirectory called images and another called masks. Corresponding image and mask .tiff files must have identical names but reside in the appropriate folder.
Instructions for labeling data correctly can be found in the Training a panoptic segmentation model tutorial. There are only two available model architectures to choose from: PanopticDeepLab and PanopticBiFPN (these are the architectures behind MitoNet_v1 and MitoNet_v1_mini, respectively). Both models predict the same targets: a semantic segmentation, an instance center heatmap, and xy offset vectors from each pixel to an associated object center (see here for details). The key difference is in the number of parameters. PanopticBiFPN has about 50% fewer (29 million compared to 55 million). In resource constrained compute environments, always opt for PanopticBiFPN. While smaller it’s still a strong architecture based on the popular EfficientDet.
By default both models use ResNet50 as the encoder. If you choose to use a Custom config it’s also possible to choose from smaller ResNet models or RegNets. The disadvantage is that none of these encoders can take advantage of CEM pretrained weights. CEM pretraining makes training a model much faster and has been shown to increase robustness and generalization (see our recent work with CEM1.5M and CEM500K). It’s strongly recommended to always leave the Use CEM pretrained weights box checked.
Similar to best practices for finetuning, the Finetunable layers parameter can control the degree of over/underfitting that occurs. Setting this field to all generally yields the best results in our experience. When compute resources are very constrained, training a PanopticBiFPN with the finetunable layer set to none is the best choice. It only requires the training of about 3 million parameters.
For training a new model the number of Iterations required is highly task dependent. As a rule of thumb, models that predict more classes and have more training data or parameters will need more iterations. 500-1,000 iterations is a great range to start with.
The Patch size in pixels controls the size of random crops used during model training. This should be set to be the same size or smaller than the patch size chosen for the training data. If using PanopticDeepLab the patch size must be divisible by 16. For PanopticBiFPN it must be divisible by 128. Larger patch sizes are typically better for segmentation models, but we’ve found that most organelles can be well captured with patches of 256.